
Aujourd’hui, avec l’essor de l’intelligence artificielle générative, une transformation profonde s’opère dans notre rapport à l’information. Les traditionnels moteurs de recherche, tels que Google, Bing, Yahoo ! …, qui ont dominé l’ère numérique en nous invitant à « chercher » nous-mêmes l’information, cèdent progressivement du terrain à des « moteurs de réponses ». Des plateformes comme Perplexity ou Gemini incarnent cette évolution ; elles ne se contentent plus de fournir des liens ou des sources, mais synthétisent l’information directement pour l’utilisateur, reformulant les données en réponses claires et immédiates.
Ce changement, s’il facilite l’accès à l’information, soulève des questions sur l’avenir des moteurs de recherche et l’écosystème qui les entourent. Ces systèmes d’IA qui agrègent et interprètent l’information à notre place, modifient la manière dont les personnes recherchent l’information et les choix proposés. Peut-on faire confiance aux réponses générées par l’IA ? Si certains pensent que les résultats présentés sont plus objectifs et exhaustifs, force est de constater que cette apparente neutralité masque en réalité une opacité dans la sélection des sources. A cela s’ajoute des limites éthiques, concernant les différents biais, l’authenticité et les abus potentiels comme le souligne Atahan Karagoz dans son étude intitulée : « Ethics and Technical Aspects of Generative AI Models in Digital Content Creation » (2024).
L’apparition d’un nouveau genre de moteurs de recherche basés sur l’IA
Les systèmes IA, en intégrant des modèles de langage avancés comme GPT, ont permis l’émergence d’un nouveau genre de moteurs de recherche. Les résultats sous forme de listes de liens ont laissé place à des réponses synthétiques, directement générées par des algorithmes capables de comprendre et de reformuler l’information. Cette évolution, incarnée par des outils comme ChatGPT, Perplexity, Gemini, Copilot, DeepSeek … offre une expérience plus fluide et plus proche du langage naturel. Pour l’internaute, c’est un gain de temps et une simplification des démarches. Pour les entreprises, c’est une opportunité de capter l’attention des utilisateurs de manière plus efficace.
Si les géants de la recherche en ligne comme Google et YouTube conservent leur domination grâce à leurs bases d’utilisateurs massives, force est de constater que la recherche par IAG gagne du terrain. En l’espace de deux ans, l’intelligence artificielle générative a bouleversé les habitudes des internautes. Des outils d’IAG comme ChatGPT, Perplexity, Gemini ou Claude sont de plus en plus utilisés pour effectuer des recherches en ligne. Selon une étude de SEMrush, ChatGPT et Gemini dominent le marché des recherches en ligne. Les internautes délaissent peu à peu les recherches classiques par mot-clé au profit de requêtes conversationnelles. On attend des réponses précises et rapides. Cette évolution questionne les entreprises sur la manière dont les contenus seront créés et optimisés à l’avenir, forçant les entreprises à penser moteur de réponse et non seulement moteur de recherche.
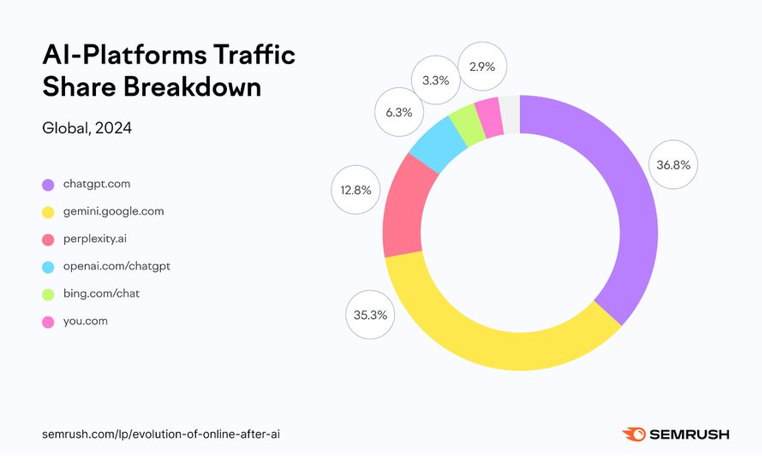
Source : SEMRUSH (2024) : https://www.semrush.com/blog/ai-search-report/
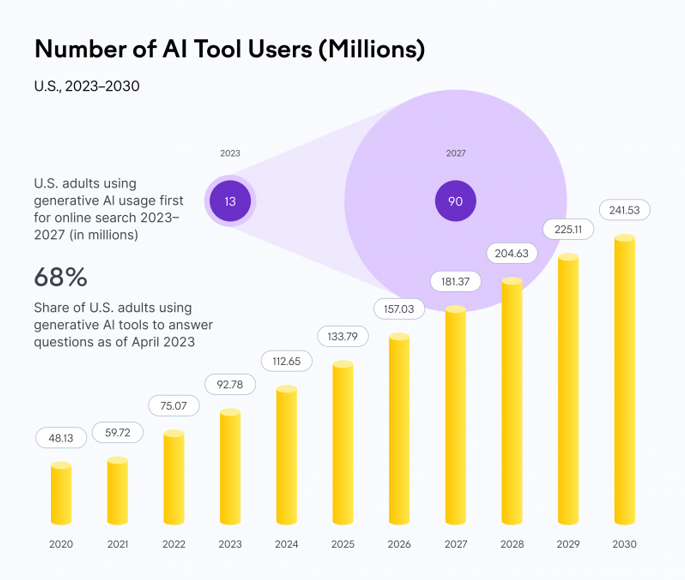
Source : SEMRUSH (2024) : https://www.semrush.com/blog/ai-search-report/
Une transformation de notre rapport à l’information et au savoir
Cette transition vers des moteurs de réponses interroge notre rapport au savoir. Dans « Petite Poucette » (2012), Michel Serres, montre que l’accès immédiat à l’information, sans effort de recherche, peut éroder notre capacité à construire une pensée critique. Les moteurs de réponse, en fournissant des conclusions prêtes à l’emploi, pourraient ainsi contribuer à une forme de « paresse intellectuelle », où l’utilisateur pourrait devenir un simple consommateur passif de connaissances prédigérées.
Le passage des moteurs de recherche aux moteurs de réponse marque une étape importante dans l’évolution de notre relation à l’information. Si ces outils offrent des opportunités indéniables en termes d’efficacité et d’accessibilité, il est plus que nécessaire de garder une certaine vigilance vis-à-vis des résultats proposés. Les réponses générées par l’IA pourraient orienter nos préférences, en mettant en avant certaines informations et en occultant d’autres. Ce phénomène, qualifié de « biais de synthèse », soulève des questions sur la transparence et la responsabilité des acteurs de l’IA. Comme le rappelle le Dominique Cardon dans « À quoi rêvent les algorithmes » (2015), si l’on veut se saisir des bonnes questions, il faut interroger les technologies à la source dans leurs conceptions et dans leurs usages, en se tournant vers les informaticiens, les data scientists, …. Les algorithmes n’agissent pas seuls, mais bien en fonction de ce que les hommes ont programmé pour leur utilisation. La technique n’est jamais neutre ; elle façonne nos pratiques et nos représentations. L’intelligence artificielle reflète, en ce sens, l’idéologie dans laquelle elle s’inscrit ; elle incarne les valeurs qui ont été à la base de son développement.
L’apparition de nouveaux défis
L’adoption massive de ces systèmes d’intelligence artificielle générative soulève des questions éthiques et économiques : qui contrôle l’information diffusée par ces IA ? Comment garantir la neutralité et l’objectivité des réponses fournies ? Quel serait l’impact sur les sites web (qui pourraient voir leur trafic diminuer au profit des réponses directes générées par l’Intelligence artificielle générative) ? Ces interrogations dessinent les contours d’un débat plus large sur la place de l’IA générative et des moteurs de réponse dans notre société.
De plus, on ne peut ignorer les implications en termes de vie privée. Les IA, pour fonctionner de manière optimale, ont besoin (de beaucoup) de données. Les recherches en ligne, les historiques de navigation, les préférences des utilisateurs : autant d’informations qui alimentent les modèles et permettent de personnaliser les réponses. La collecte et l’utilisation de ces données posent des questions cruciales en matière de protection des droits individuels. Dans cette logique, OpenAI et Microsoft ont accusé DeepSeek d’avoir utilisé les données d’OpenAI sans l’autorisation de ce dernier en ayant recours à la distillation pour entraîner ses propres modèles. C’est un peu ironique, car OpenAI a lui aussi utilisé des contenus et des données non négligeables du web – sans consentement, sans se préoccuper des droits d’auteurs – pour entraîner ses propres modèles !
Au total, l’IA transforme indéniablement la recherche en ligne en la rendant plus accessible et plus performante, mais elle introduit également de nouveaux défis. Entre promesses technologiques et risques éthiques et informationnels, il revient aux acteurs du numérique, aux scientifiques, aux régulateurs et aux citoyens de veiller à ce que cette révolution profite à tous, sans sacrifier la qualité de l’information, ni les libertés fondamentales, à commencer par celle de « s’informer ». Comme souvent avec les avancées technologiques, un équilibre doit être trouvé. Dans cette logique, Warda Baïliche auteure de « L’Humain à l’ère de l’IA » (2024), nous invite à une prise de conscience collective sur les responsabilités qui incombent à chacun dans la construction d’un avenir où l’IA serait au service de l’humain, et non l’inverse !
